
Dynamic Programming (Click Here!)
Full code can be provided upon request
Introduction
Autonomous robotic navigation is a fundamental aspect of modern robotics, essential for enabling robots to operate independently in complex and dynamic environments. The development of advanced navigation systems, which integrate sensors, algorithms, and learning techniques, aims to improve safety, reduce human labor, and expand the range of tasks robots can perform. These advancements are particularly crucial for applications in hazardous or inaccessible areas, where human presence is impractical or dangerous.
Markov Decision Process and Dynamic Programming in Autonomous Navigation
A Markov Decision Process (MDP) provides a mathematical framework for decision-making in environments where outcomes are partly random and partly controlled. In autonomous navigation, MDPs are used to determine the optimal path a robot should take in a stochastic environment. Dynamic Programming (DP) is a technique used to solve MDPs efficiently, enabling autonomous systems to evaluate the long-term consequences of their actions and ensuring that chosen paths are globally optimal.
Project Objective
The primary goal of this project is to design and implement a dynamic programming algorithm to guide an autonomous agent through a “Door & Key” environment. The agent, represented by a red triangle, must navigate to a goal location, depicted as a green square, which may be obstructed by a closed door. The agent may need to pick up a key to unlock the door, all while minimizing energy costs associated with actions such as moving, turning, picking up a key, and unlocking a door. The project includes two main scenarios: (A) a “Known Map” scenario with specific environments, and (B) a “Random Map” scenario requiring a robust control policy for various random environments.
Problem Formulation
Action Space
The action space U includes the following actions: Move Forward (MF), Turn Left (TL), Turn Right (TR), Pick Up Key (PK), and Unlock Door (UD), each associated with an energy cost.
State Space: Part A
The state space X is defined by the agent’s position, direction, whether it has the key, and whether it has reached the goal. The agent’s direction is encoded as LEFT = 0, UP = 1, RIGHT = 2, DOWN = 3. States where the agent’s position coincides with walls are excluded.
Motion Model: Part A
The agent’s motion model describes how actions affect its state:
- Move Forward (MF): Moves the agent in its current direction unless obstructed by a wall or closed door.
- Turn Left (TL) and Turn Right (TR): Changes the agent’s direction.
- Pick Up Key (PK): Attempts to pick up a key if it is directly in front of the agent.
- Unlock Door (UD): Unlocks a door if the agent has a key and the door is directly in front.
Extended State Space Definition: Part B
In the “Unknown Environment” task, the state space is extended to include possible configurations of keys, doors, and goal locations, allowing the agent to adapt to different map layouts.
Motion Model: Part B
The motion model for Part B includes similar actions but with additional checks for key and door locations, ensuring that the agent adapts to the discovered environment.
Time Horizon
The time horizon ( T ) is defined as the cardinality of the state space X minus one, reflecting the maximum number of transitions the agent might make.
Cost Functions
- Intermediate Cost Function: Assigns a cost of 1 to each action, except when the action leads directly to the goal.
- Terminal Cost Function: Assigns a cost of zero if the agent reaches the goal, and infinity otherwise.
Technical Approach
Dynamic Programming Algorithm Implementation
The dynamic programming algorithm is implemented to solve the MDP for autonomous navigation. It uses inputs like state and action sets, cost functions, and transition probabilities to compute an optimal policy that minimizes the expected cost over time.
Solving for Known and Unknown Environments
- Known Map Scenario:
- The dynamic programming algorithm was applied to predefined environments, calculating the optimal policy for each specific layout.
- Random Map Scenario:
- The algorithm was adapted to handle unknown environments by extending the state space and recalculating the optimal policy as the agent discovered new information.
Results
Known Environment
Figure 1: Direct environment.
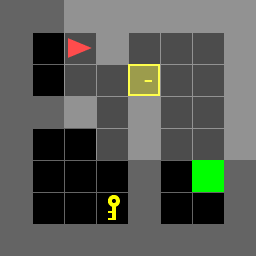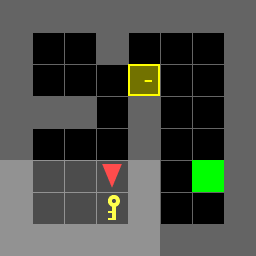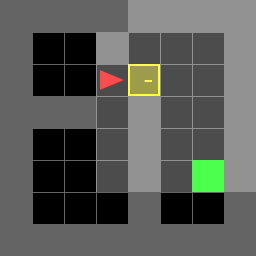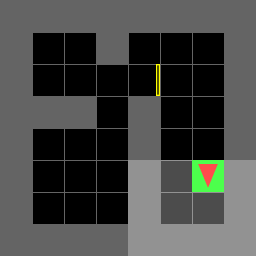
Random Environment
Figure 2: Random environment.
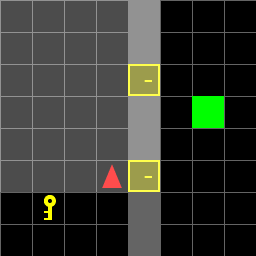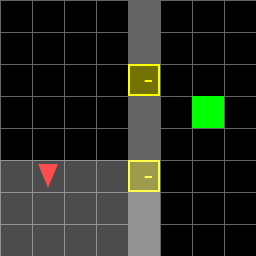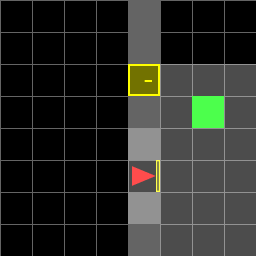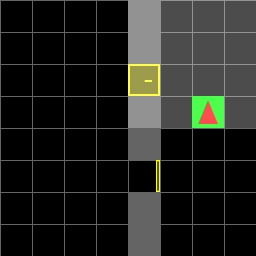
Paths for various environments are detailed, showing the actions taken by the agent in each scenario. The agent successfully navigates to the goal, either directly or by first obtaining a key when necessary.
Conclusion
The dynamic programming algorithm effectively computed optimal navigation policies for both known and unknown environments. The algorithm’s adaptability and robustness were demonstrated through its success in handling diverse and dynamic challenges in the simulation scenarios, validating its potential for real-world applications in autonomous robotic navigation.