
Infinite-Horizon Stochastic Optimal Control (Click Here!)
Full code can be provided upon request
Introduction
The project focuses on the critical importance of trajectory tracking for differential-drive robots, which are prevalent in various applications. These robots, with two independently driven wheels, require precise control to navigate complex environments safely and effectively. Ensuring reliable trajectory tracking is essential not only for operational efficiency but also for safety, especially in scenarios where robots interact with humans or navigate through hazardous areas. The project aims to explore advanced algorithms to improve the adaptability and safety of these robots.
Receding-Horizon Certainty Equivalent Control (CEC)
The CEC algorithm is key to trajectory tracking, operating by continuously updating control decisions based on a predictive model over a finite future horizon. This approach optimizes control actions at each step using current state estimates, treating future states as known and fixed to simplify computation. CEC is widely used in applications requiring precise control and adaptability, such as autonomous vehicles and robotic manipulators, due to its ability to handle dynamic environments effectively.
General Policy Iteration (GPI)
GPI is a reinforcement learning framework well-suited for complex decision-making tasks like trajectory tracking. It improves both the policy (action strategy) and the value function (long-term return estimate) iteratively. This adaptability makes GPI effective in environments that may change or require the robot to learn from interactions without explicit programming for every scenario. GPI’s iterative process ensures that the robot’s trajectory becomes increasingly optimal, making it valuable for tasks such as navigation and obstacle avoidance in dynamic settings.
Problem Formulation
The project focuses on designing a control system for a ground differential-drive robot to follow a desired trajectory while avoiding obstacles. The robot’s state is defined by its position and orientation, with control inputs being linear and angular velocities. The kinematic model of the robot includes motion noise, and the control inputs are bounded to ensure realistic movement. The primary goal is to design a control policy that allows the robot to follow a reference trajectory in an environment with obstacles, ensuring safe navigation through free space.
Certainty Equivalent Control (CEC)
CEC simplifies the control problem by treating the effects of noise as negligible, focusing on optimizing a deterministic control problem. This approach approximates an infinite-horizon problem by solving a series of finite-horizon problems iteratively, using a non-linear programming (NLP) framework. CEC continuously re-plans the control inputs at each step, adapting to the current state of the robot while maintaining a focus on minimizing deviations from the desired trajectory.
General Policy Iteration (GPI)
GPI addresses the stochastic optimal control problem by discretizing the state and control spaces, allowing the robot to evaluate and improve its policy iteratively. The state space is discretized into a grid, with transition probabilities precomputed to expedite the process. GPI incorporates safety constraints to avoid collisions, using adaptive discretization to balance computational efficiency with solution accuracy. This method enables the robot to refine its trajectory tracking strategy over time, ensuring more precise control in complex environments.
Technical Approach
CEC Implementation
CEC is implemented using CasADi for nonlinear optimization, focusing on minimizing a cost function over a finite time horizon. The method begins with an initialization phase, setting parameters like time horizon and discount factors. The core function calculates control inputs based on current and reference states, optimizing for position and orientation errors while considering control costs. Constraints are applied to ensure the feasibility of control inputs and avoid obstacles, with the NLP solver providing the optimal control inputs for each step.
GPI Implementation
GPI involves discretizing the state space into grids to make the problem computationally feasible. The control space is also discretized, with transition probabilities and stage costs precomputed for efficiency. Collision avoidance is handled by assigning higher costs to states near obstacles, discouraging paths through these regions. The GPI algorithm iteratively evaluates and improves the policy until it converges to an optimal strategy, balancing the trade-offs between position error, orientation error, and control effort.
Results
Part A: CEC Implementation
The CEC implementation effectively follows the reference trajectory, though it occasionally comes close to obstacles due to unaccounted environmental noise. The CEC method is fast, likely due to optimized underlying code, but it sometimes deviates significantly from the trajectory or scrapes obstacles.
Figure 1: CEC Control Policy. 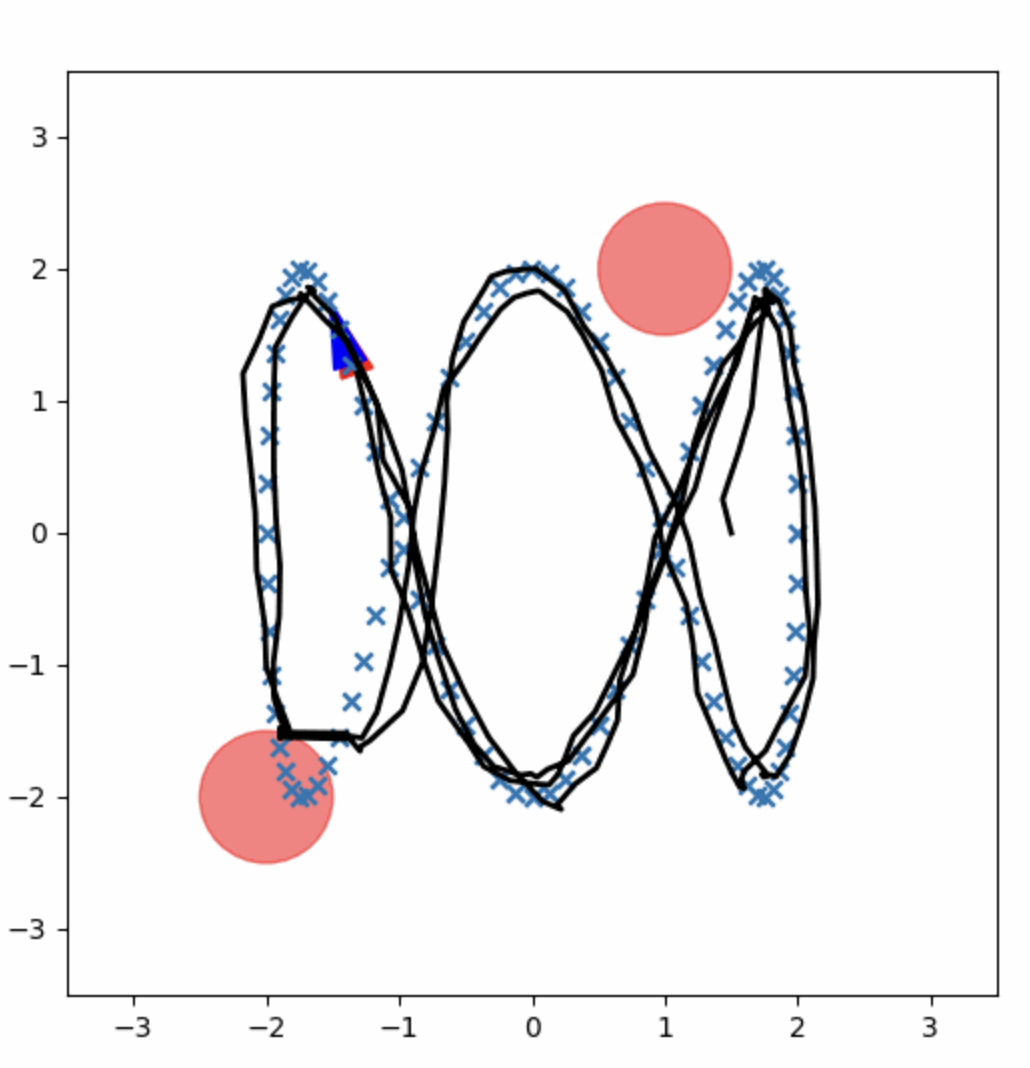
Part B: GPI Implementation
The GPI implementation follows the reference trajectory but struggles in certain scenarios, particularly at the edges of the trajectory. The control and input space discretization may be a factor, and while GPI is computationally intensive, it provides a robust framework for improving trajectory tracking.
Figure 2: GPI Control Policy.
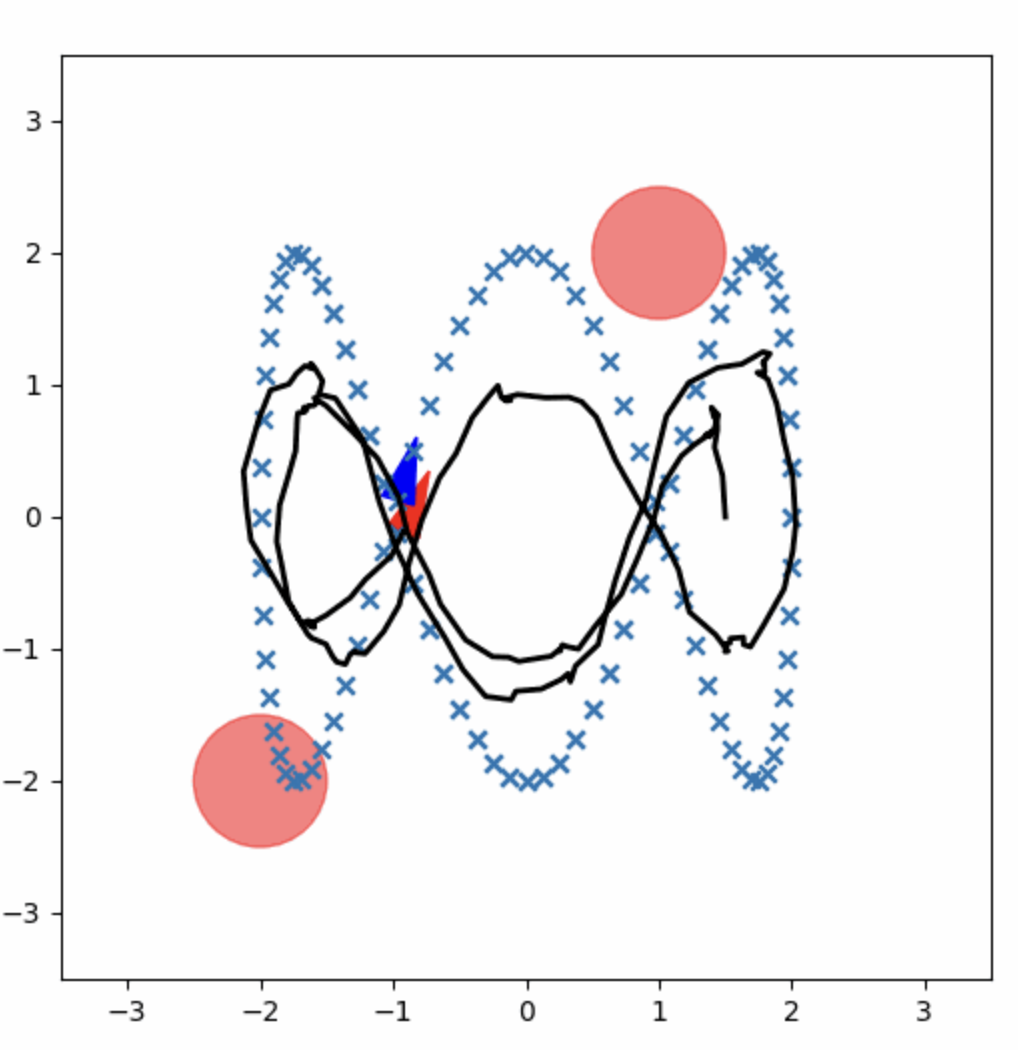 | 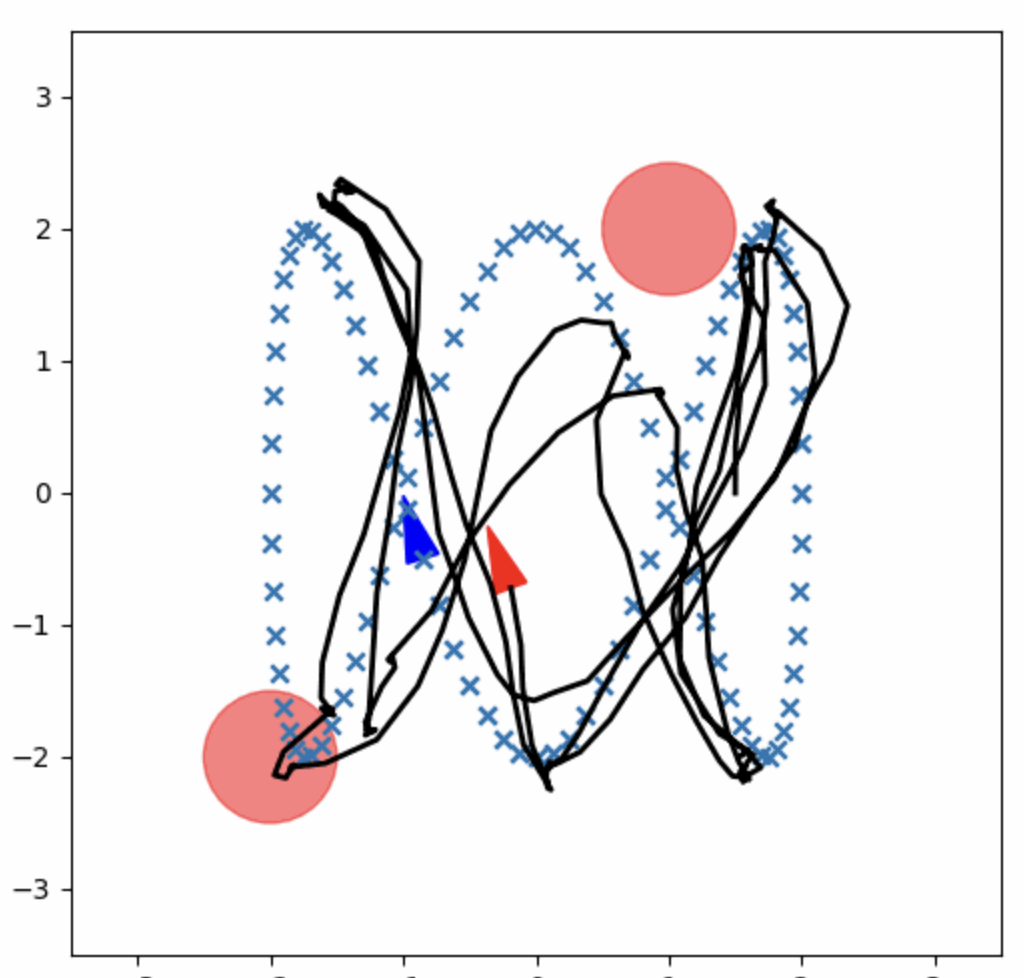 |
Conclusion
The project demonstrates the strengths and limitations of CEC and GPI for trajectory tracking in differential-drive robots. CEC offers efficient performance but may overlook environmental noise, leading to minor deviations and collisions. GPI, while robust and adaptive, is computationally intensive and struggles with certain edge cases. Future work could focus on integrating noise management into CEC and refining GPI discretization methods to enhance overall performance in dynamic environments.